#include <Kokkos_Core.hpp>#include <algorithm>#include <iostream>#include <vector>#include <mpi.h>#include "timer_macro.hpp"#include "domain_decomposition.hpp"#include "sort.hpp"#include "transpose_particles.hpp"#include "get_current_triangles.hpp"#include "shift.hpp"#include "globals.hpp"
Functions | |
| template<int PTL_N_DBL, class DataType , class MPIDevice > | |
| void | copy_to_send_buffer (Particles::Array< DataType, DeviceType > &local_particles, int n_staying, Kokkos::View< OneParticle< PTL_N_DBL > *, MPIDevice > &buf) |
| template void | transpose_and_shift< ParticleDataTypes > (Kokkos::View< int *, HostType > &sendcnt, Kokkos::View< int *, HostType > &sdispls, Kokkos::View< int *, HostType > &recvcnt, Kokkos::View< int *, HostType > &rdispls, Particles::Array< ParticleDataTypes, DeviceType > &local_particles, int n_staying, int n_leaving, int n_arriving, const MyMPI &mpi) |
| template void | transpose_and_shift< PhaseDataTypes > (Kokkos::View< int *, HostType > &sendcnt, Kokkos::View< int *, HostType > &sdispls, Kokkos::View< int *, HostType > &recvcnt, Kokkos::View< int *, HostType > &rdispls, Particles::Array< PhaseDataTypes, DeviceType > &local_particles, int n_staying, int n_leaving, int n_arriving, const MyMPI &mpi) |
| template<int PTL_N_DBL> | |
| void | send_recv_all_to_all (OneParticle< PTL_N_DBL > *sendbuf_ptr, View< int *, HostType > &sendcnt_t, View< int *, HostType > &sdispls_t, OneParticle< PTL_N_DBL > *recvbuf_ptr, View< int *, HostType > &recvcnt_t, View< int *, HostType > &rdispls_t, const MyMPI &mpi, bool use_all_to_all) |
| template<class DataType > | |
| void | transpose_and_shift (Kokkos::View< int *, HostType > &sendcnt, Kokkos::View< int *, HostType > &sdispls, Kokkos::View< int *, HostType > &recvcnt, Kokkos::View< int *, HostType > &rdispls, Particles::Array< DataType, DeviceType > &local_particles, int n_staying, int n_leaving, int n_arriving, const MyMPI &mpi) |
| void | setup_even_distribution (const DomainDecomposition< DeviceType > &pol_decomp, int local_n_ptl, const View< int *, CLayout, HostType > &sort_count) |
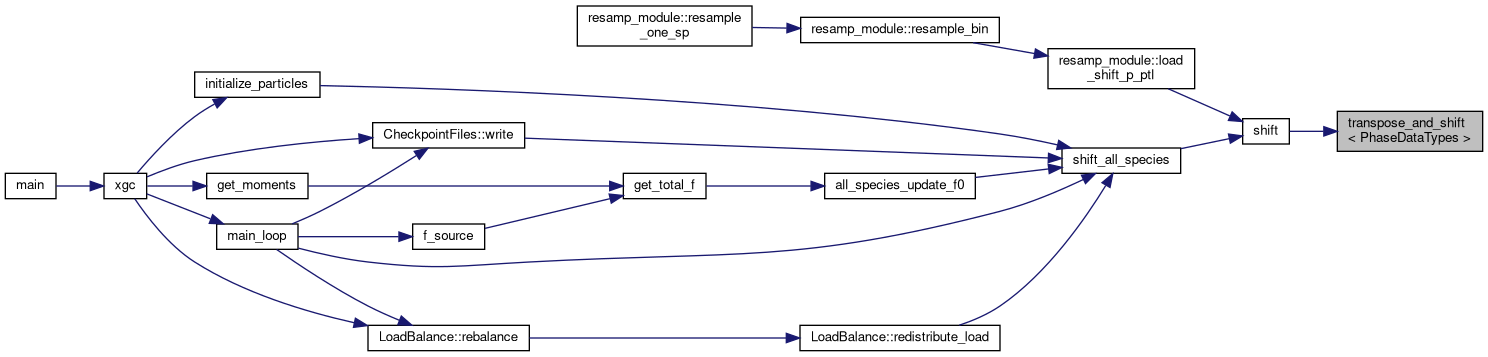
| void | shift (Species< DeviceType > &species, SortViews< DeviceType > &sort_views, const Grid< DeviceType > &grid, const MagneticField< DeviceType > &magnetic_field, const DomainDecomposition< DeviceType > &pol_decomp, ShiftOptions options) |
| void | shift_all_species (Plasma &plasma, const Grid< DeviceType > &grid, const MagneticField< DeviceType > &magnetic_field, const DomainDecomposition< DeviceType > &pol_decomp, bool evenly_distribute_ptl) |
Function Documentation
◆ copy_to_send_buffer()
| void copy_to_send_buffer | ( | Particles::Array< DataType, DeviceType > & | local_particles, |
| int | n_staying, | ||
| Kokkos::View< OneParticle< PTL_N_DBL > *, MPIDevice > & | buf | ||
| ) |


◆ send_recv_all_to_all()
| void send_recv_all_to_all | ( | OneParticle< PTL_N_DBL > * | sendbuf_ptr, |
| View< int *, HostType > & | sendcnt_t, | ||
| View< int *, HostType > & | sdispls_t, | ||
| OneParticle< PTL_N_DBL > * | recvbuf_ptr, | ||
| View< int *, HostType > & | recvcnt_t, | ||
| View< int *, HostType > & | rdispls_t, | ||
| const MyMPI & | mpi, | ||
| bool | use_all_to_all | ||
| ) |

◆ setup_even_distribution()
| void setup_even_distribution | ( | const DomainDecomposition< DeviceType > & | pol_decomp, |
| int | local_n_ptl, | ||
| const View< int *, CLayout, HostType > & | sort_count | ||
| ) |
◆ shift()
| void shift | ( | Species< DeviceType > & | species, |
| SortViews< DeviceType > & | sort_views, | ||
| const Grid< DeviceType > & | grid, | ||
| const MagneticField< DeviceType > & | magnetic_field, | ||
| const DomainDecomposition< DeviceType > & | pol_decomp, | ||
| ShiftOptions | options | ||
| ) |
Shifts particles between MPI ranks. First the particles are sorted by destination rank The particles are packed into a buffer and sent with an MPI all-to-all Then they are unpacked from the receiving buffer back into the particle AoSoA The same is done for phase0, needed for ions
- Parameters
-
[in,out] species contains the particles [in] sort_views is needed for the sort [in] grid is needed for the sort [in] magnetic_field is needed for the sort [in] pol_decomp is needed for the sort and shift
- Returns
- void
◆ shift_all_species()
| void shift_all_species | ( | Plasma & | plasma, |
| const Grid< DeviceType > & | grid, | ||
| const MagneticField< DeviceType > & | magnetic_field, | ||
| const DomainDecomposition< DeviceType > & | pol_decomp, | ||
| bool | evenly_distribute_ptl | ||
| ) |
Shifts particles between MPI ranks. First the particles are sorted by destination rank The particles are packed into a buffer and sent with an MPI all-to-all Then they are unpacked from the receiving buffer back into the particle AoSoA The same is done for phase0, needed for ions
- Parameters
-
[in,out] plasma contains all species info [in] grid is needed for the sort [in] magnetic_field is needed for the sort [in] pol_decomp is needed for the sort
- Returns
- void
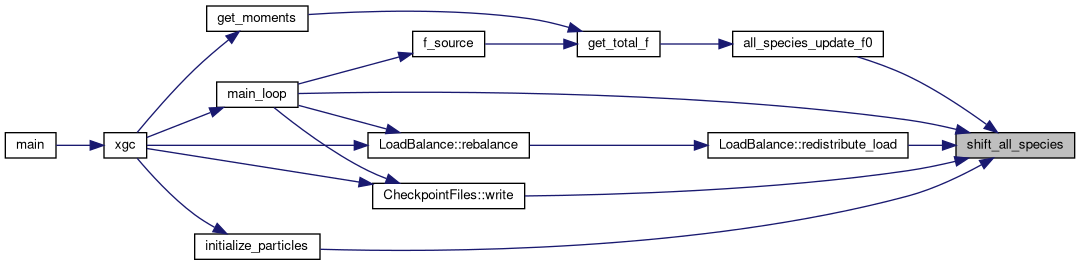
◆ transpose_and_shift()
| void transpose_and_shift | ( | Kokkos::View< int *, HostType > & | sendcnt, |
| Kokkos::View< int *, HostType > & | sdispls, | ||
| Kokkos::View< int *, HostType > & | recvcnt, | ||
| Kokkos::View< int *, HostType > & | rdispls, | ||
| Particles::Array< DataType, DeviceType > & | local_particles, | ||
| int | n_staying, | ||
| int | n_leaving, | ||
| int | n_arriving, | ||
| const MyMPI & | mpi | ||
| ) |
Packs particles into a send buffer and shifts them between MPI ranks. If particles are on the device and GPU-aware MPI is off, the send buffer resides on the host and there is a receive buffer on the host as well. If not, then the host buffer is on device and there is no receive buffer because the arriving particles are brought straight to the paticle array. The function is templated on the size of the particle (in doubles) and the particle data type. This is done so that phase0 can be sent with the same routine
- Parameters
-
[in] sendcnt is the number of particles getting sent to each rank [in] sdispls is the displacement in the send buffer of each rank [in] recvcnt is the number of particles getting received from each rank [in] rdispls is the displacement in the recv buffer of each rank [in,out] local_particles is where the particles are located on device [in] n_staying is the number of particles staying on this rank [in] n_leaving is the number of particles leaving this rank [in] n_arriving is the number of particles arriving to this rank [in] mpi contains MPI and domain decomposition parameters
- Returns
- void
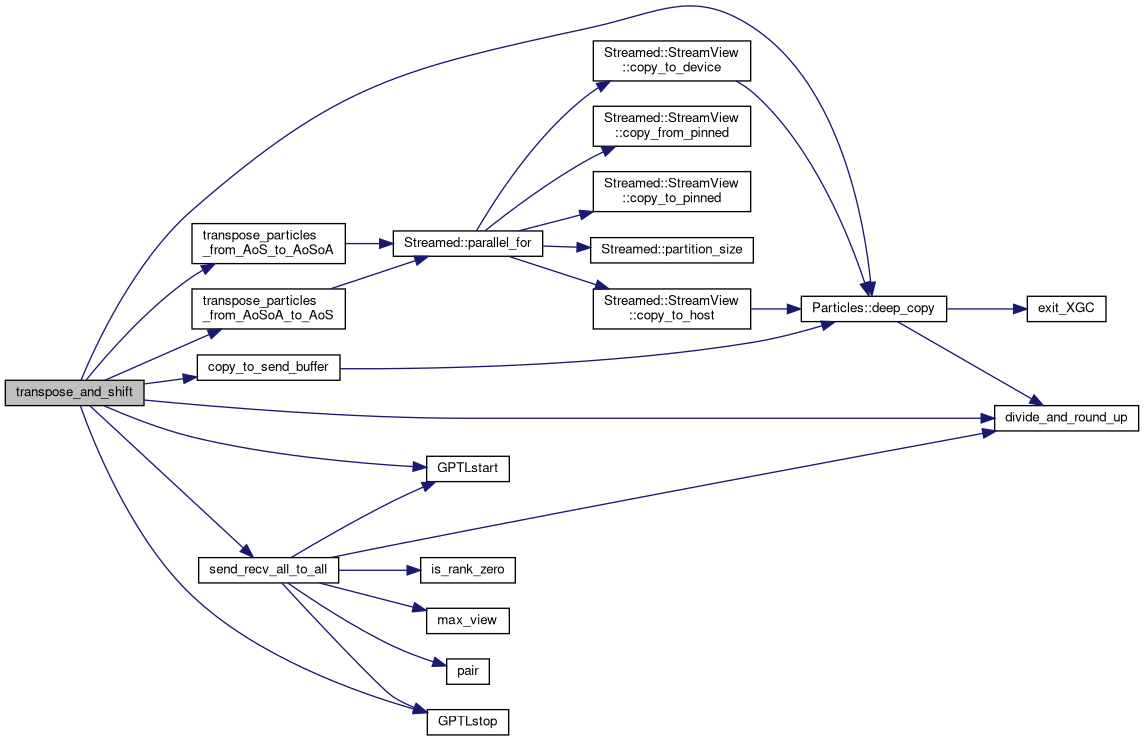
◆ transpose_and_shift< ParticleDataTypes >()
| template void transpose_and_shift< ParticleDataTypes > | ( | Kokkos::View< int *, HostType > & | sendcnt, |
| Kokkos::View< int *, HostType > & | sdispls, | ||
| Kokkos::View< int *, HostType > & | recvcnt, | ||
| Kokkos::View< int *, HostType > & | rdispls, | ||
| Particles::Array< ParticleDataTypes, DeviceType > & | local_particles, | ||
| int | n_staying, | ||
| int | n_leaving, | ||
| int | n_arriving, | ||
| const MyMPI & | mpi | ||
| ) |
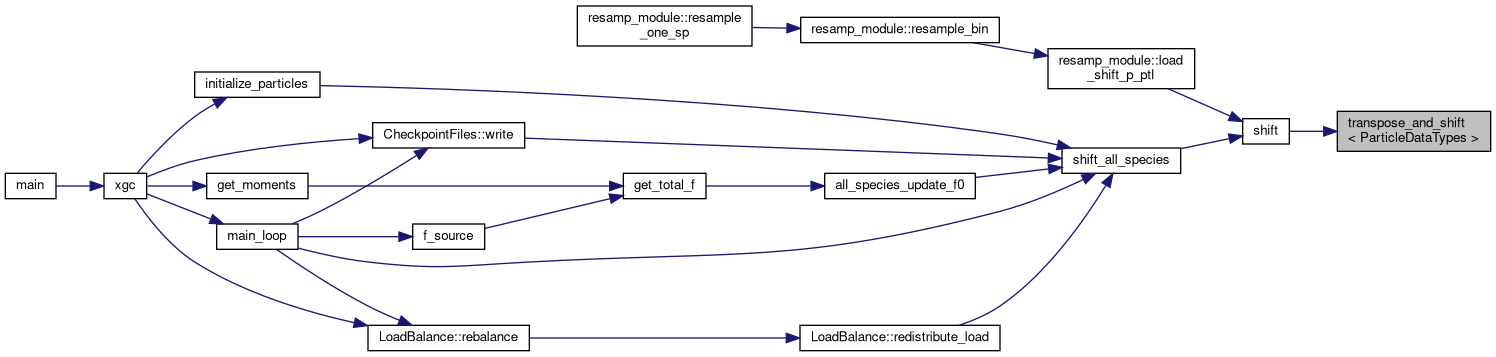
◆ transpose_and_shift< PhaseDataTypes >()
| template void transpose_and_shift< PhaseDataTypes > | ( | Kokkos::View< int *, HostType > & | sendcnt, |
| Kokkos::View< int *, HostType > & | sdispls, | ||
| Kokkos::View< int *, HostType > & | recvcnt, | ||
| Kokkos::View< int *, HostType > & | rdispls, | ||
| Particles::Array< PhaseDataTypes, DeviceType > & | local_particles, | ||
| int | n_staying, | ||
| int | n_leaving, | ||
| int | n_arriving, | ||
| const MyMPI & | mpi | ||
| ) |